
 5
5






- 입력 2025.02.13 08:43


 0
0[ 아시아경제 ] 인공지능은 인간이 가진 추론 능력을 어디까지 모방할 수 있을까? 오픈AI가 챗GPT에 적용된 거대언어모델(LLM)인 GPT-4는 언어 능력과 기억력에서 큰 발전을 이루었지만, 실제 논리적 사고나 추론 능력은 여전히 제한적이라는 평가를 받는다.
특히 LLM의 추론 능력에 대한 정의가 모호할 뿐 아니라, 기존 평가 방법은 주로 결과 중심적이어서 LLM이 어떻게 사고하고 추론하는지를 객관적·포괄적으로 평가하는 방법이 명확하지 않았다.

김선동 광주과학기술원(GIST) AI융합학과 교수 연구팀이 LLM의 추론 능력을 정량적으로 측정할 수 있는 새로운 프레임워크를 개발했다고 13일 밝혔다.
연구팀은 인간의 인지 과정이 '사고 언어'로 매개된다는 인지심리학의 '사고 언어 가설(Language of Thought Hypothesis, LoTH)'을 기반으로 LLM의 추론 과정을 평가하는 방법을 제시했다.
이 가설에 따르면, 인간의 추론 과정은 논리적 일관성, 구성성, 생성성의 세 가지 특징을 가진다. 이 세 가지 요소에 초점을 맞춘 연구팀은 생성형 인공지능(AI) 분야에서 LLM의 성능을 평가하는 기준 데이터세트인 '벤치마크 데이터세트 ARC'를 통해 프로세스 중심 방식으로 LLM의 추론 및 문맥 이해 능력을 평가하는 새로운 접근 방식을 도출했다.
먼저, 논리적 일관성을 측정하기 위해 LLM이 문제를 해결할 때 일관된 정답을 도출하는지를 실험했다. 연구팀은 동일한 문제를 변형한 '증강 문제'를 만들어 LLM이 변형된 문제에서도 동일한 논리를 유지하는지를 분석했다. 이를 통해 LLM의 논리적 일관성이 프롬프팅(지시) 방법에 따라 차이를 보인다는 점을 확인했다.
구성성(조합 능력)을 평가하기 위해 LLM이 문제를 해결하는 데 필요한 개념들을 얼마나 효과적으로 조합하는지도 실험했다. 전체 과정을 고려해 개별 개념을 조합하는 인간에 비해 LLM은 조합해야 할 단계가 많아질수록 정확도가 떨어지는 모습을 보였다.
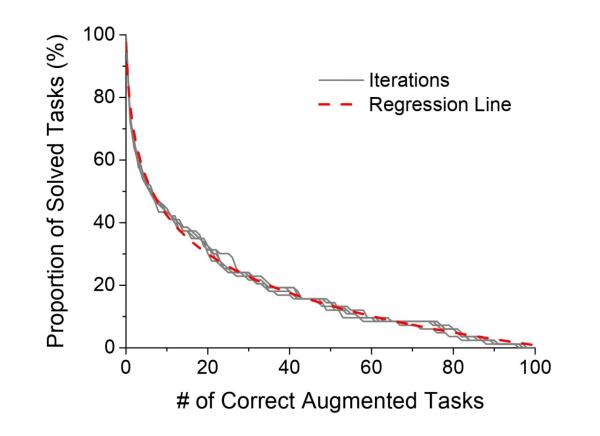
LLM의 생성성을 평가하기 위해 제약 조건에 맞는 유효한 결과를 얼마나 많이 생성하는지도 실험했다. 이를 위해 연구팀은 ARC 문제를 여러 개의 카테고리로 나누고, 역방향의 새로운 프롬프팅 방식을 제시했다.
또한 연구팀은 LLM의 추론 능력을 과정 중심으로 분석하는 실험법을 제시했으며, 이 과정에서 LLM뿐만 아니라 추론 AI 개발에 필요한 LLM을 활용한 프로그램 합성법, 프롬프팅 기법을 통한 데이터 증강법 등을 제안했다.
LLM의 추론 능력을 정량적으로 측정한 결과, 논리적 일관성 부문에서 증강(변형) 문제에 대해 평균 18.2%의 정확도를, 구성성 부문에서 조합 과제에 대해 5~15%의 정확도를, 생성성 부문에서는 17.12%의 생성 타당도를 보였다.
연구팀은 LLM이 일부 추론 능력을 보이지만, 계획 단계가 길고 입출력 이미지가 복잡해지면 단계적인 추론을 거치지 못해 이 세 가지 측면(논리적 일관성, 구성성, 생성성)에서 한계를 보이며, 인간과 비교했을 때 추론 능력은 여전히 뒤처져 있다고 분석했다.
김선동 교수는 "이전의 LLM 평가 방식이 특정 벤치마크에 의한 성능 측정에 치중했지만, 이번 연구는 LLM의 추론 과정과 인간의 차이를 분석한 것이 특징"이라면서 "향후 AI 로봇을 비롯한 인공지능 시스템이 인간 수준의 추론 능력을 갖추는 데 기여할 것으로 기대한다"고 말했다.
AI융합학과 김선동 교수의 지도로 이승필 학사과정생, 심우창 석사과정생, 신동현 석사과정생이 수행한 이번 연구는 국제학술지 'ACM Transactions on Intelligent Systems and Technology(TIST)'에 지난달 20일 온라인 게재됐다.
김종화 기자 justin@asiae.co.kr<ⓒ투자가를 위한 경제콘텐츠 플랫폼, 아시아경제(www.asiae.co.kr) 무단전재 배포금지>
- #언어
- #인간
- #거대
- #추론
- #논리
- #능력
- #모델
- #과정
- #생성
- #평가

- 기뻐요
- 0

- 응원해요
- 0

- 실망이에요
- 0

- 슬퍼요
- 0
- 1
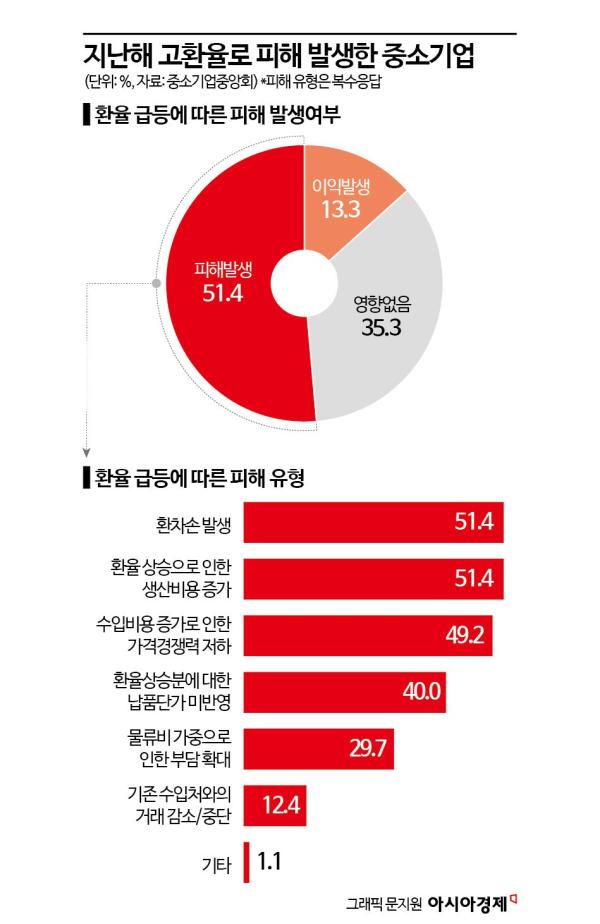
- 中企 절반은 고환율로 피해…"적정 환율은 1304원"
- 아시아경제
 0
0
- 2
- ‘승리의 여신: 니케’ X ‘에반게리온’ 2차 콜라보레이션 개시
- 중앙이코노미뉴스
- 0

- 3
- '새로' 칼로리는 얼마?…롯데칠성음료, '푸드 QR' 도입
- 아시아경제
- 0

- 4
- 네덜란드 경제부 장관·ASML 전 CEO, 삼성 평택공장 방문
- 아시아경제
- 0

- 5
- 27세 여부장, 호텔 수영장 사고 극복하려다 '환대의 AI'가 탄생했다[일본人사이드]
- 아시아경제
- 0
![27세 여부장, 호텔 수영장 사고 극복하려다 '환대의 AI'가 탄생했다[일본人사이드]](https://cdn.inappnews.net/news/683078/ian-1740196815-691098.jpg)
- 6
- BBQ 한마리 시키면 치즈볼 주더니…3일간 매출 3배 뛰었다
- 아시아경제
- 0

- 7
- SM엔터, 디어유 지분 11.4% 추가 취득…"IP 비즈니스 확장"
- 아시아경제
- 0

- 8
- "'다이소' 때문에 마트에 갔어요"…매출 '껑충' 일등공신 된 사연
- 아시아경제
- 0

- 9
- NHN, ‘한게임 섯다&맞고’에 최상위 경쟁 콘텐츠 ‘독도수호전’과 ‘독도공방전’ 추가
- 중앙이코노미뉴스
- 0

- 10
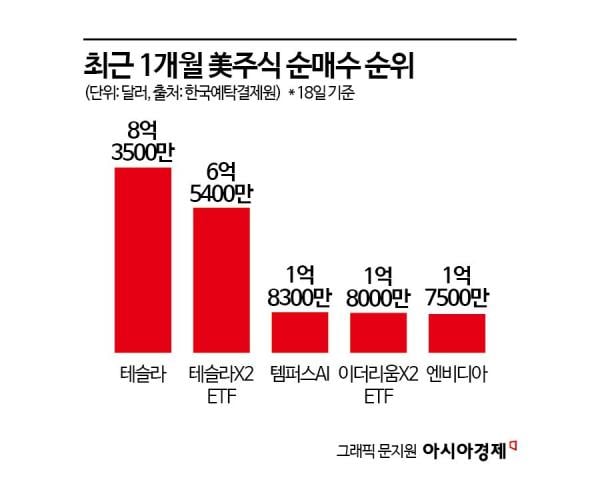
- "엔비디아 제쳤다"…서학개미가 쓸어담은 이 종목
- 아시아경제
- 0
- 최신뉴스
- 인기뉴스
- 뉴스
- 투표
- 게임
- 이벤트

최신순
추천순
답글순

등록된 댓글이 없습니다.