
 5
5





- 권숙희 기자
- 입력 2025.01.31 14:33


 0
0중국과학원 물리연구소, AI테스트 결과 공개
딥시크, 인간과 경쟁시 '3등'…인간 최고점엔 한참 밀려

[로이터 연합뉴스 자료사진. 재판매 및 DB 금지]
(서울=연합뉴스) 권숙희 기자 = 중국 인공지능(AI) 스타트업 딥시크(DeepSeek, 深度求索) 최신 모델의 물리학 문제 해결 능력이 AI 선두주자인 챗GPT(ChatGPT)를 능가했다는 주장이 중국에서 나왔다.
중국과학원 물리연구소는 소셜미디어 공식 계정을 통해 최근 개최한 물리 경시대회의 AI 테스트 결과를 지난 30일 공개하며 이같이 밝혔다.
딥시크의 AI 모델이 벤치마크 테스트 결과 복잡한 문제 해결에서 수학·코딩에 이르기까지 미국 주요 기업들의 최신 AI 모델을 능가한 것으로 알려진 가운데, 중국 국영 연구소에서 과학 수재들이 경쟁하는 경시대회 문제를 이용해 실험을 진행한 것이다.
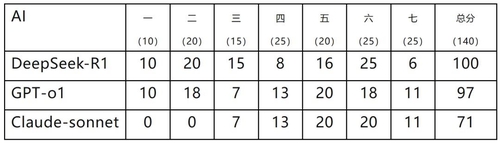
연구소는 이달 17일 장쑤성에서 열린 '톈무(天目)배 이론물리 경시대회'에서 출제된 문제를 AI가 풀도록 한 결과 딥시크의 최신 모델인 R1의 점수가 오픈AI의 GPT-o1을 제쳤다고 밝혔다.
연구소는 딥시크의 R1, 오픈AI의 GPT-o1, 앤스로픽의 클로드 소넷 등 3개 AI 모델이 푼 문제의 답안을 실제 경시대회 채점위원단에게 전달했다고 밝혔다.
연구소는 "AI 응답을 통해 시험 진행 방식에 대한 이해도를 확인한 후 시험을 시작했다"면서 "총 문제 7개에 대해 순차적으로 답안을 받았으며, 답안에 대해서는 중간에 어떤 피드백도 제공하지 않았다"고 설명했다.
채점 결과 140점 만점에 딥시크가 100점으로 1등을 차지했으며, 다음으로 챗GPT이 97점, 클로드 소넷이 71점을 받았다.
다만, 이번 대회 참가자들과 진짜 경쟁할 경우 딥시크는 3등 수준의 성적이었으며, 인간 최고점인 '125점'과는 격차가 매우 컸다.
연구소는 "이제 연구원이나 박사후연구원(Postdoc·포닥)을 뽑을 필요도 없는 걸까"라면서도 "AI의 사고 과정이 뛰어난 것은 사실이나, 기본적 실수에서 헤매는 경향이 있는 것으로 나타났다"고 지적했다.
[중국과학원 물리연구소 위챗 계정 캡처. 재판매 및 DB금지]
연구소는 항목별 채점 결과를 공유하며 흥미로운 사실도 분석했다.
연구소는 "딥시크와 비교하면 챗GPT의 답안은 인간이 작성한 것과 더 유사한 스타일을 보였다"면서 "챗GPT가 증명 문제에서 상대적으로 높은 점수를 기록했다"고 분석했다.
이어 "딥시크는 '증명'의 의미를 제대로 이해하지 못했다"면서 "증명해야 할 결론을 재서술했을 뿐 증명 과정을 답안에 포함하지 않았다"고 덧붙였다.
또 "클로드 소넷은 예상외로 부진한 성적을 나타냈다"면서 "초반 두 문제에서 0점을 받는 실수를 저질렀으며, 후반으로 가서는 챗GPT와 유사한 부분에서 감점을 받았다"고 덧붙였다.
한편, 딥시크는 AI 모델이 다른 모델의 출력 결과를 훈련 목적으로 사용, 유사한 기능을 개발하는 '증류'(distillation) 기술을 통해 무단으로 다른 AI 기업의 데이터를 수집했다는 의혹을 받고 있다.
이 때문에 '저비용 개발'로 전세계를 놀라게 한 딥시크가 다른 기업의 성과를 훔쳐 온 것인지, 자체적으로 혁신을 일궈낸 것인지 한동안 논란이 계속될 전망이라고 미국 자유아시아방송(RFA) 등은 지적했다.

[중국과학원 물리연구소 위챗 계정 캡처. 재판매 및 DB금지]
suki@yna.co.kr
- #문제
- #답안
- #모델
- #시크
- #GPT
- #경시
- #대회
- #중국과학원
- #테스트
- #연구소

- 기뻐요
- 0

- 응원해요
- 0

- 실망이에요
- 0

- 슬퍼요
- 0
- 1
- 출장갔던 한인 변호사도 美여객기 사고로 희생…동포사회 '애도'
- 연합뉴스
 0
0

- 2
- 딥시크, "오픈AI기술 훔쳤나" 질문에 부인…中논객 '대리 항변'
- 연합뉴스
- 0

- 3
- 日세븐일레븐 창업가, 태국 재벌에 지원 요청…캐나다 인수 대항
- 연합뉴스
- 0

- 4
- '멕시코만→미국만' 이름분쟁 격화…멕시코, 구글에 항의서한
- 연합뉴스
- 0

- 5
- 미 SEC, 비트코인·이더리움 결합 ETF 초기 승인
- 연합뉴스
- 0

- 6
- 트럼프, 여객기 참사 원인으로 뜬금없이 '다양성 정책' 지목
- 연합뉴스
- 0

- 7
- 대만 총통, 여소야대 갈등 지속에 "여야 협력 필요" 강조
- 연합뉴스
- 0

- 8
- 美 SEC, 비트코인·이더리움 결합 ETF 초기 승인
- 아시아경제
- 0

- 9
- 가자지구에 미국인 용병 첫 배치…美민간보안업체 계약
- 연합뉴스
- 0

- 10
- 국민아이돌 '성상납 의혹' 여파…"광고수입 2200억 감소 전망" 나온 후지TV
- 아시아경제
- 0

- 최신뉴스
- 인기뉴스
- 뉴스
- 투표
- 게임
- 이벤트

최신순
추천순
답글순

등록된 댓글이 없습니다.